
Drag queens e Inteligência Artificial: computadores devem decidir o que é ‘tóxico’ na internet?
Plataformas de internet como Facebook, Twitter e YouTube sofrem pressão de maneira constante para atuar de maneira mais firme na moderação dos conteúdos que circulam nas redes sociais. Em razão do grande volume de conteúdos postados por usuários, essas empresas começaram a desenvolver inteligência artificial para automatizar processos decisórios envolvendo remoção de conteúdo. Essas tecnologias envolvem o uso de machine learning e são específicas para diferentes tipos de conteúdo, tais como imagens, vídeos, sons e texto escrito. Algumas dessas ferramentas, desenvolvidas para avaliar o nível de “toxicidade” de conteúdos textuais, fazem uso de processamento natural de linguagem e análise de sentimentos para detectar discurso de ódio e conteúdo de caráter danoso.
Discurso LGBTQ: conteúdo “tóxico” pode desempenhar papel positivo?
Muito embora essas tecnologias possam representar um ponto de inflexão nos debates sobre discurso de ódio e conteúdo danoso nas redes sociais, pesquisas recentes indicam que elas ainda não conseguem entender contexto ou detectar a intenção e a motivação do enunciador, falhando em reconhecer o valor social de determinadas formas de conteúdo – inclusive discurso LGBTQ visando ressignificar palavras usualmente empregadas para atacar membros da comunidade. Além disso, há número considerável de estudos que indicam o uso de linguagem “pseudo-ofensiva” como forma de interação que serve para preparar membros da comunidade LGBTQ para lidar com hostilidade externa ao grupo [1] [2] [3] [4].
Alguns desses estudos focaram especificamente nos códigos comunicacionais de drag queens. Justamente por trabalhar com papéis de gênero e identidade, as drag queens sempre foram importantes e tiveram voz ativa dentro da comunidade LGBTQ. Elas usam, com frequência, linguagem que pode ser considerada dura ou desrespeitosa ao construir o seu discurso. Ao olhar para seus estilos de comunicação, acadêmicos identificaram que “uma língua afiada é uma arma desenvolvida com uso frequente, e é um recurso de sobrevivência para aqueles que se encontram fora de círculos privilegiados […] [elas] utilizam sua percepção e formulação rápida para demandar aceitação – ou para aniquilar aqueles que a neguem. Esse comportamento é, quase literalmente, autodefesa”. Nesse sentido, “[…] falas, as quais podem ser consideradas potencialmente desrespeitosas fora de um contexto apropriado, podem ser avaliadas positivamente por membros do grupo que reconheçam a importância de se ‘construir uma casca grossa’ como forma de enfrentar um ambiente hostil”.
Como a IA está sendo usada para detectar conteúdo “tóxico” na internet?
Existem diversas ferramentas de IA que estão sendo desenvolvidas para entender, identificar e localizar conteúdos “tóxicos” ou “danosos” na internet. Nossa pesquisa testa o Perspective, uma tecnologia desenvolvida pela Jigsaw (do grupo Alphabet) que mede o nível de toxicidade de conteúdo de texto. O Perspective define “tóxico” como “comentário rude, desrespeitoso ou não-razoável que provavelmente fará com que você abandone uma discussão”. Segundo a Jigsaw, o modelo de toxicidade foi treinado por meio do ranqueamento, por parte de usuários de internet, de comentários disponíveis na rede em uma escala que variava entre “muito tóxico” e “muito saudável”. Os níveis de toxicidade apontados pelo Perspective indicam a probabilidade (de 0 a 100%) de um determinado conteúdo textual ser considerado “tóxico”.
Ao treinar seu algoritmo para descobrir que conteúdos têm maior probabilidade de serem considerados “tóxicos”, o Perspective pode ser uma ferramenta útil para tomada automatizada de decisões sobre o que devem permanecer e o que deve ser removido de plataformas de internet. Tais decisões são sensíveis e políticas, tendo em vista que podem ter implicações claras para o exercício da liberdade de expressão e outros direitos humanos. Com o passar dos anos, o debate sobre o papel das plataformas de internet enquanto curadoras de conteúdo tornou-se significativamente mais complexo, especialmente no que diz respeito ao uso de IA.
Como a pesquisa foi feita?
Nós utilizamos a API do Perspective para medir os níveis de toxicidade de tweets postados por drag queens conhecidas nos Estados Unidos e comparar os resultados com aqueles obtidos com a análise de tweets de outros usuários famosos da plataforma, especialmente figuras da extrema direita. As contas analisadas foram selecionadas a partir de lista de participantes do reality show “RuPaul’s Drag Race”, popular nos Estados Unidos e no exterior – inclusive no Brasil -, especialmente entre membros da comunidade LGBTQ.
Por meio do acesso à API do Twitter coletamos tweets de todas as ex-participantes de RuPaul’s Drag Race (temporadas 1 a 10) com contas verificadas na plataforma, o que resultou na análise de 80 perfis de drag queens.
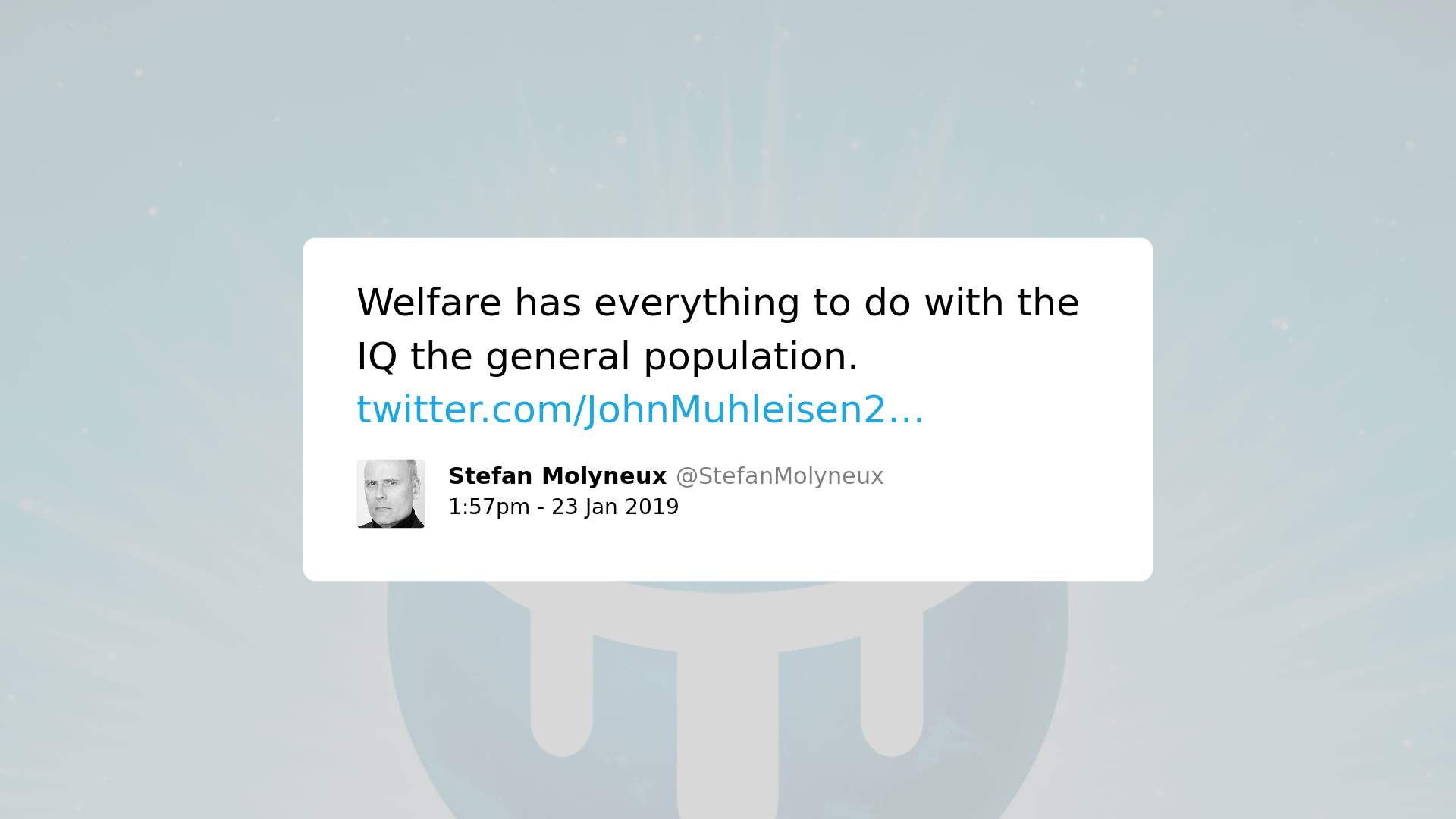
Nós utilizamos a 6ª versão do modelo de toxicidade (“toxicity”) do Perspective. Submetemos à análise apenas conteúdos em inglês, de modo que precisamos excluir da análise tweets redigidos em outras línguas. Coletamos também tweets de pessoas não-LGBTQ conhecidas (Michelle Obama, Donald Trump, David Duke, Richard Spencer, Stefan Molyneux e Faith Goldy). Essas pessoas foram escolhidas como amostras de controle para discurso menos controverso ou “saudável” (Michelle Obama) e para discurso extremamente controverso ou “muito tóxico” (Donald Trump, David Duke, Richard Spencer, Stefan Molyneux e Faith Goldy). No total, coletamos 116.988 tweets e analisamos 114.204 (depois de exclusões) deles.
Um algoritmo python foi desenvolvido para coletar e analisar todos os tweets em quatro passos. Primeiro, os tweets foram coletados e armazenados em um banco de dados CSV. Apenas três atributos foram armazenados: o nome do autor do tweet, o horário da postagem e o seu conteúdo. Um identificador também foi criado e armazenado. O passo seguinte envolveu a limpeza e pré-processamento do conteúdo, o que inclui a remoção de links de imagens, bem como de caracteres (tais como ‘, “, …) e a tradução de emojis em texto. Na sequência, os tweets foram submetidos à API do Perspective com o objetivo de obter o seu nível provável de toxicidade. Na última etapa, as probabilidades retornadas pela API foram armazenadas em um novo banco de dados CSV juntamente com o conteúdo dos tweets e a sua identificação. Com esse novo banco de dados foi possível analisar o quão tóxico os tweets das drag queens de RuPaul’s Drag Race são de acordo com o Perspective.
Principais resultados
No gráfico abaixo (clique na imagem para ampliar), as drag queens estão em azul, os supremacistas brancos, em vermelho. Michelle Obama está em verde e Donald Trump, em laranja.

Os resultados indicam que um número significativo de perfis das drag queens no Twitter foram considerados como potencialmente mais tóxicos que o perfil de Donald Trump e de supremacistas brancos. Em média, os níveis de toxicidade das drag queens variam entre 16,68% e 37,81%, enquanto que os níveis dos supremacistas brancos variam entre 21,30% e 28,87%, e o de Trump fica em 21,84%.
Também realizamos testes para medir os níveis de toxicidade de palavras usualmente encontradas em tweets de drag queens. A maior parte dessas palavras foram consideradas significativamente tóxicas: BITCH – 98.18%; FAG – 91.94%; SISSY – 83.20%; GAY – 76.10%; LESBIAN – 60.79%; QUEER – 51.03%; TRANSVESTITE – 44.48%.
Isso significa que, independentemente do contexto, palavras como gay, lesbian e queer já são consideradas como significativamente tóxicas, o que aponta a existência de vieses no Perspective. Adicionalmente, muito embora outras palavras como fag, sissy e bitch possam ser usualmente consideradas “tóxicas”, estudos queer sobre linguística indicam como o uso de palavras como essas por membros da comunidade LGBTQ desempenham um papel relevante e positivo.
Como o uso de linguagem “pseudo-ofensiva” foi identificado como forma de interação que serve para preparar membros da comunidade LGBTQ para lidar com hostilidade externa ao grupo, análises automatizadas que desconsiderem essa função social do discurso podem ter repercussões significativas na capacidade de membros da comunidade de reclamar esses termos e reforçar vieses danosos.
Uma possível razão para tais distorções e vieses é o desafio que a análise do contexto representa para tecnologias baseadas em inteligência artificial. O Perspective parece apoiar-se, em grande medida, no nível “geral” de toxicidade de palavras específicas ao invés de analisar a toxicidade de ideias ou ideologias, o que pode ser muito contextual. Essas discrepâncias provavelmente também têm origem em vieses presentes nos dados usados para treinar a ferramenta de inteligência artificial, assunto que é tópico de intenso debate no âmbito da comunidade das ciências da computação.
Como isso pode ter impacto concreto sobre o discurso LGBTQ?
Recentemente, a Jigsaw lançou o Tune, plugin experimental para navegador (atualmente apenas disponível para o Chrome) o qual usa o Perspective para permitir aos usuários ajustarem para cima e para baixo o “volume” do conteúdo online que desejam ver. No lançamento, o Tune funciona em diferentes redes sociais, o que inclui Facebook, Twitter, YouTube e Reddit. Usuários podem “aumentar o volume” para verem tudo ou “diminuir o volume” até o “modo zen” para substituir comentários tóxicos por pequenos pontos coloridos. O Tune se vende como uma forma de combater “o abuso e o assédio que tiram a atenção de discussões na internet”, “usando Perspective para ajudar os usuários a focarem no que importa”.
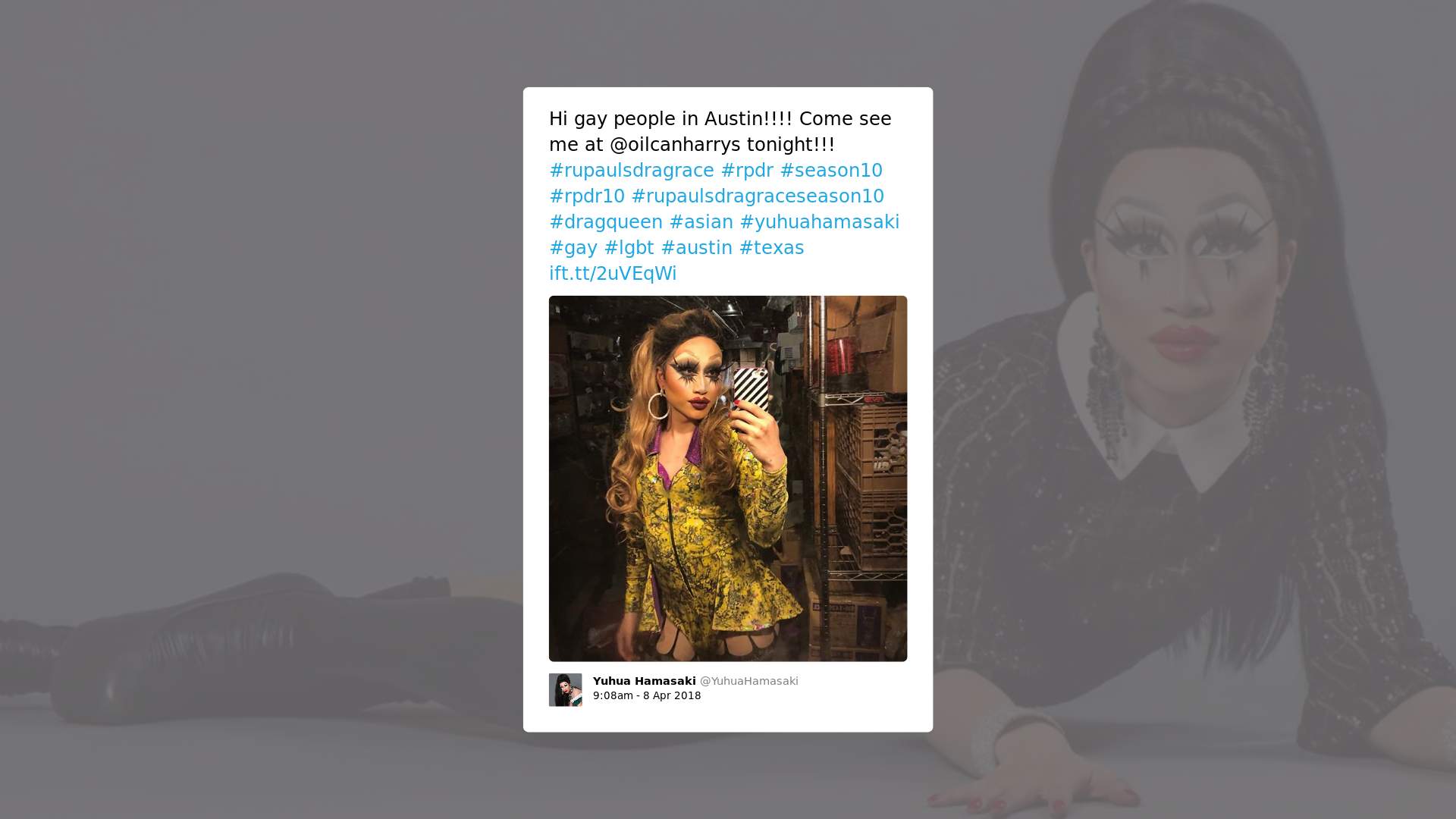
No modo “esconder tudo”, o perfil no Twitter da drag queen Yuhua Hamasaki fica assim:
Os pontos roxos representam tweets que foram ocultados. Voltando à nossa pesquisa, quando considerados individualmente, 3.925 tweets das drag queens tiveram seu potencial de toxicidade avaliado em 80% ou mais (cerca de 3,7% do total de tweets analisados), o que significaria que ficariam todos ocultados de usuários do Tune.
Nossa análise qualitativa de tweets individuais ilustram como esses vieses têm implicações significativas para o discurso LGBTQ. Se ferramentas de inteligência artificial com vieses embutidos forem implementadas para remover, policiar, censurar ou moderar conteúdos na internet que possam ter impactos profundos na capacidade de membros da comunidade LGBTQ de levantar a voz e reclamar o uso de palavras “tóxicas” ou “ofensivas” para propósitos legítimos, como podemos ver abaixo.
1. Casos em que o conteúdo deveria ser considerado neutro, mas foi possivelmente considerado tóxico pelo Perspective em razão do uso de uma palavra específica, como “gay” ou “lesbian”:
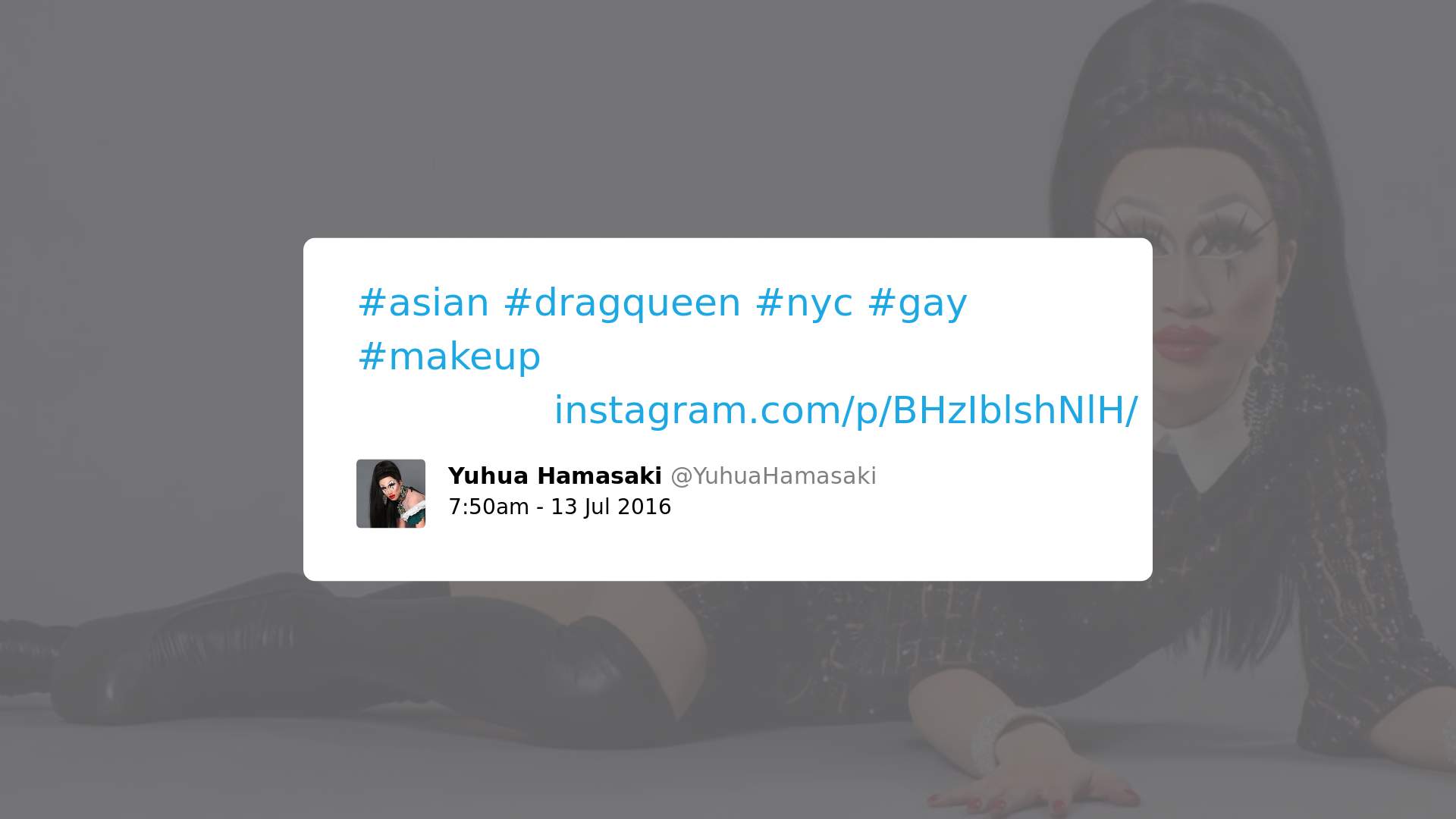
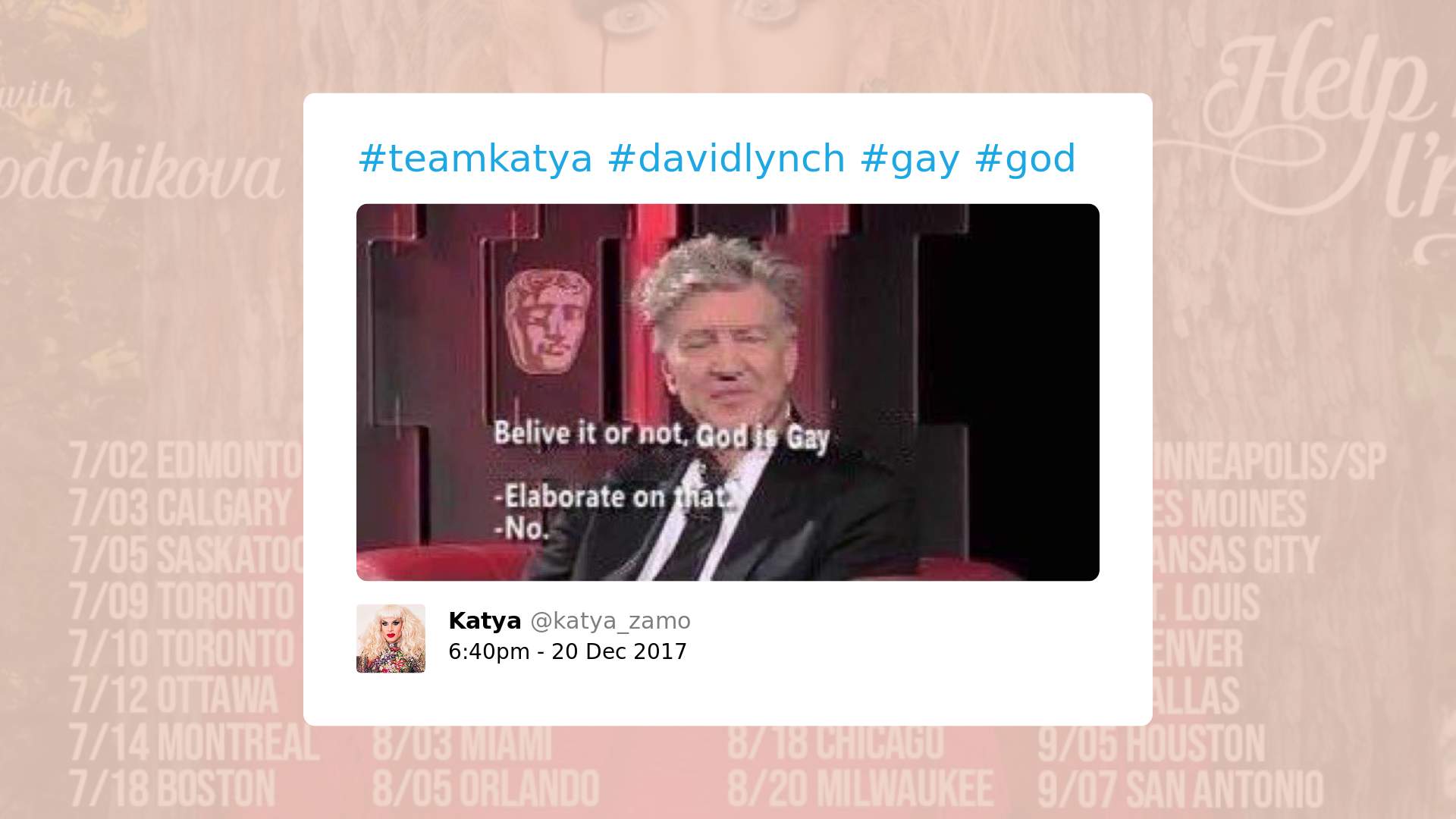
2. Casos em que uma palavra usada é considerada ofensiva em outro contexto, mas pode possuir sentido diferente no discurso LGBTQ (inclusive sentido positivo):
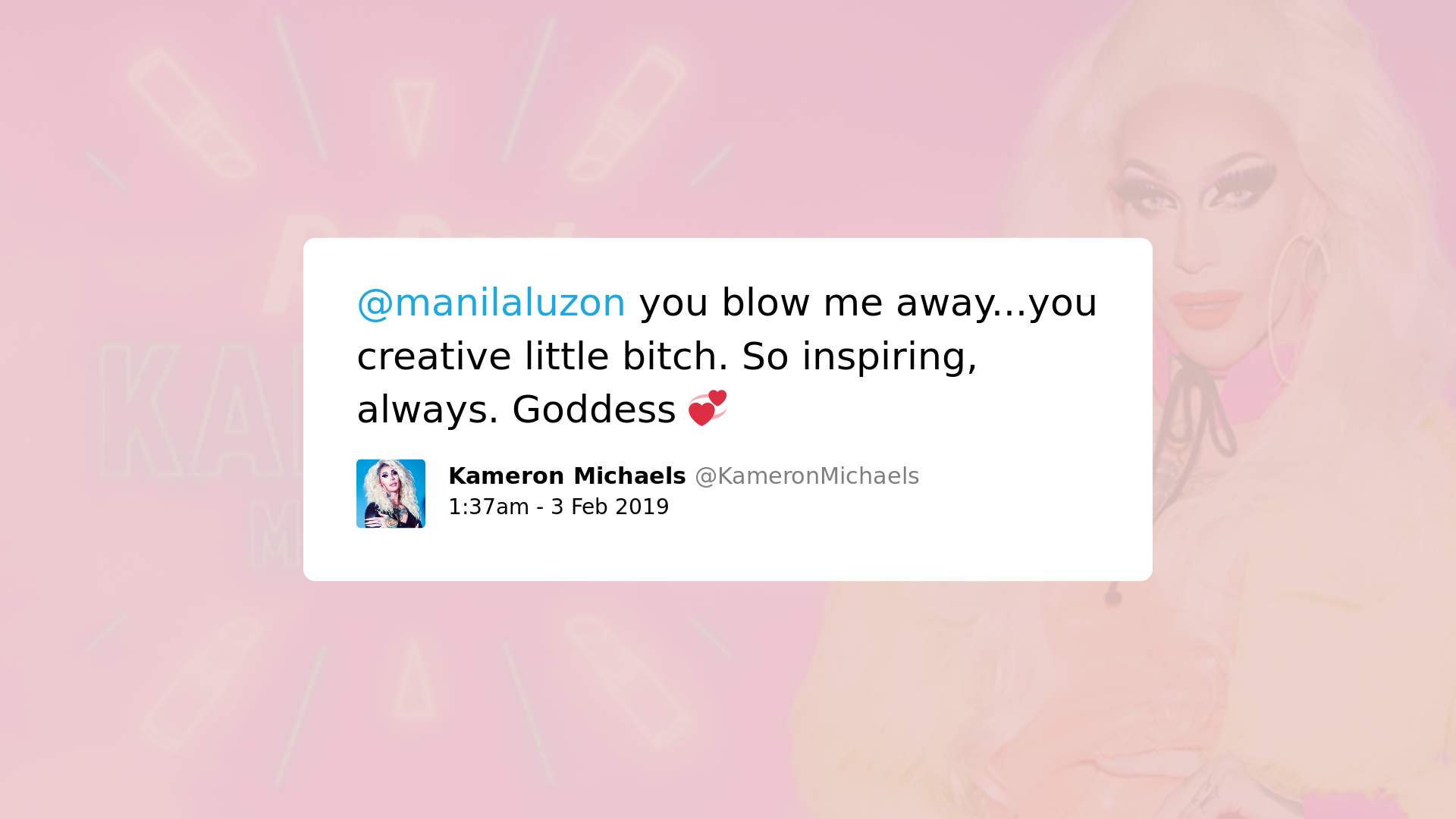
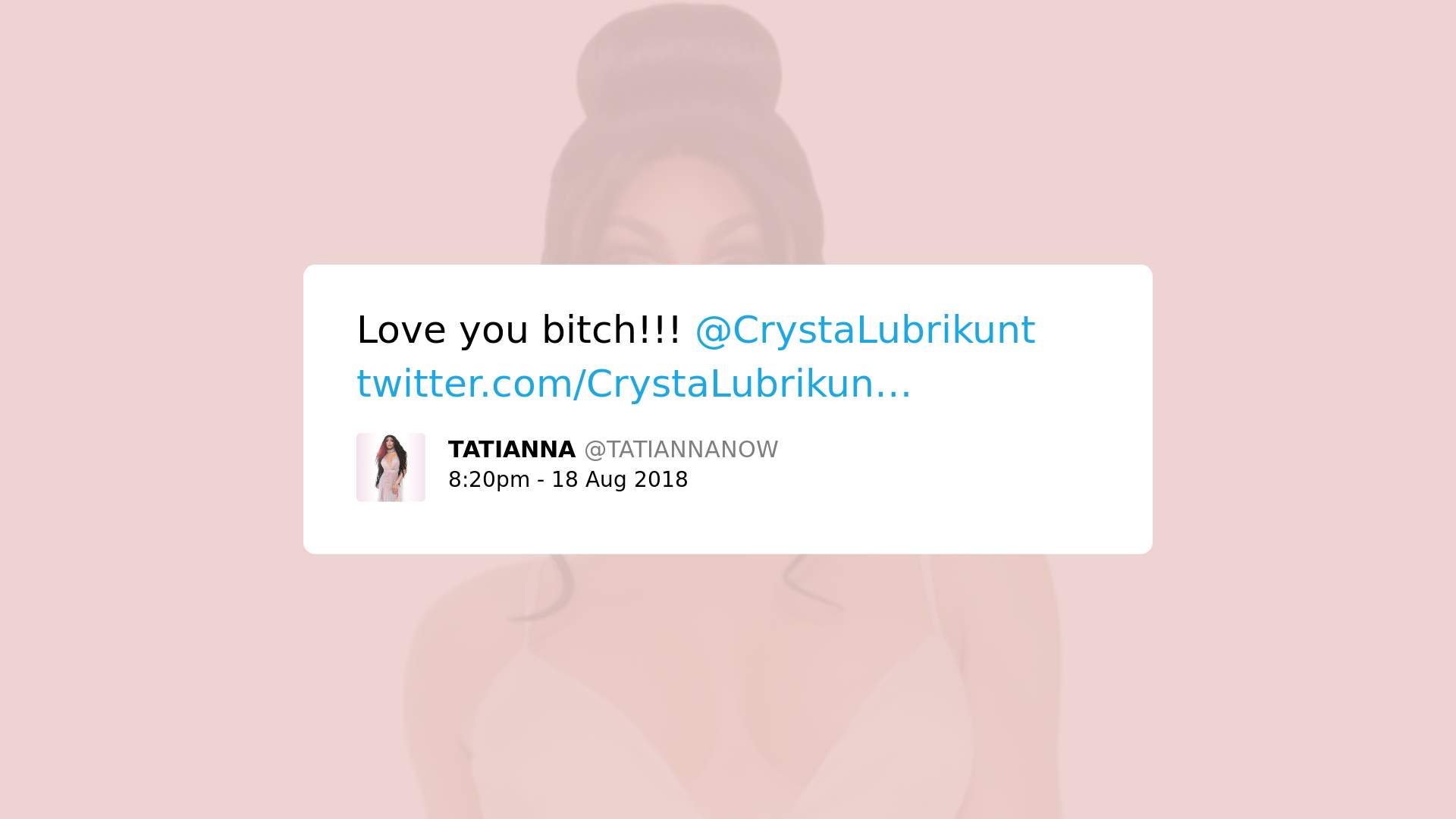

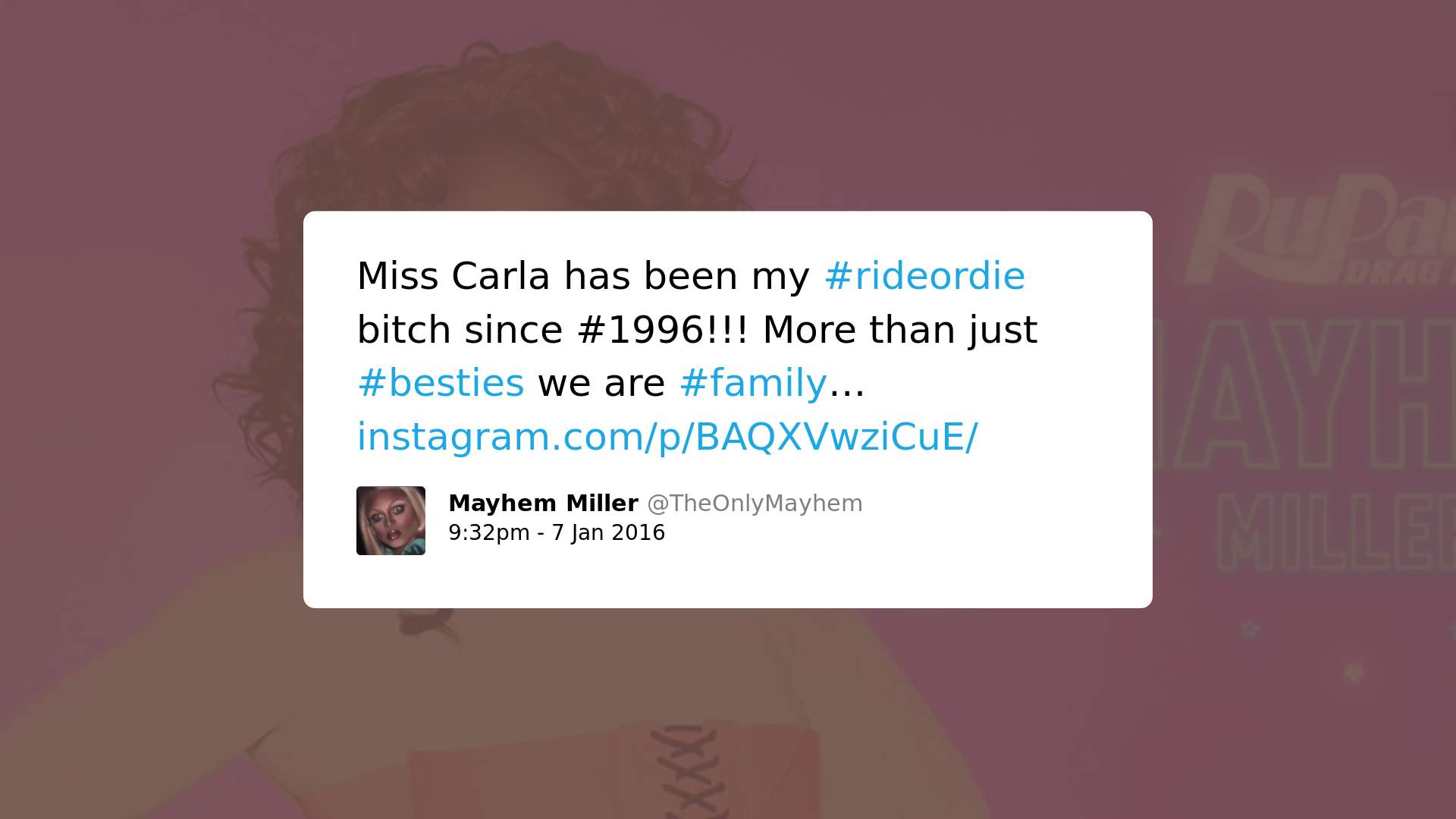
3. Contêm palavras/expressões usualmente usadas para atacar pessoas LGBTQ, mas tenta ressignificá-las com o objetivo de torná-las neutras ou positivas:
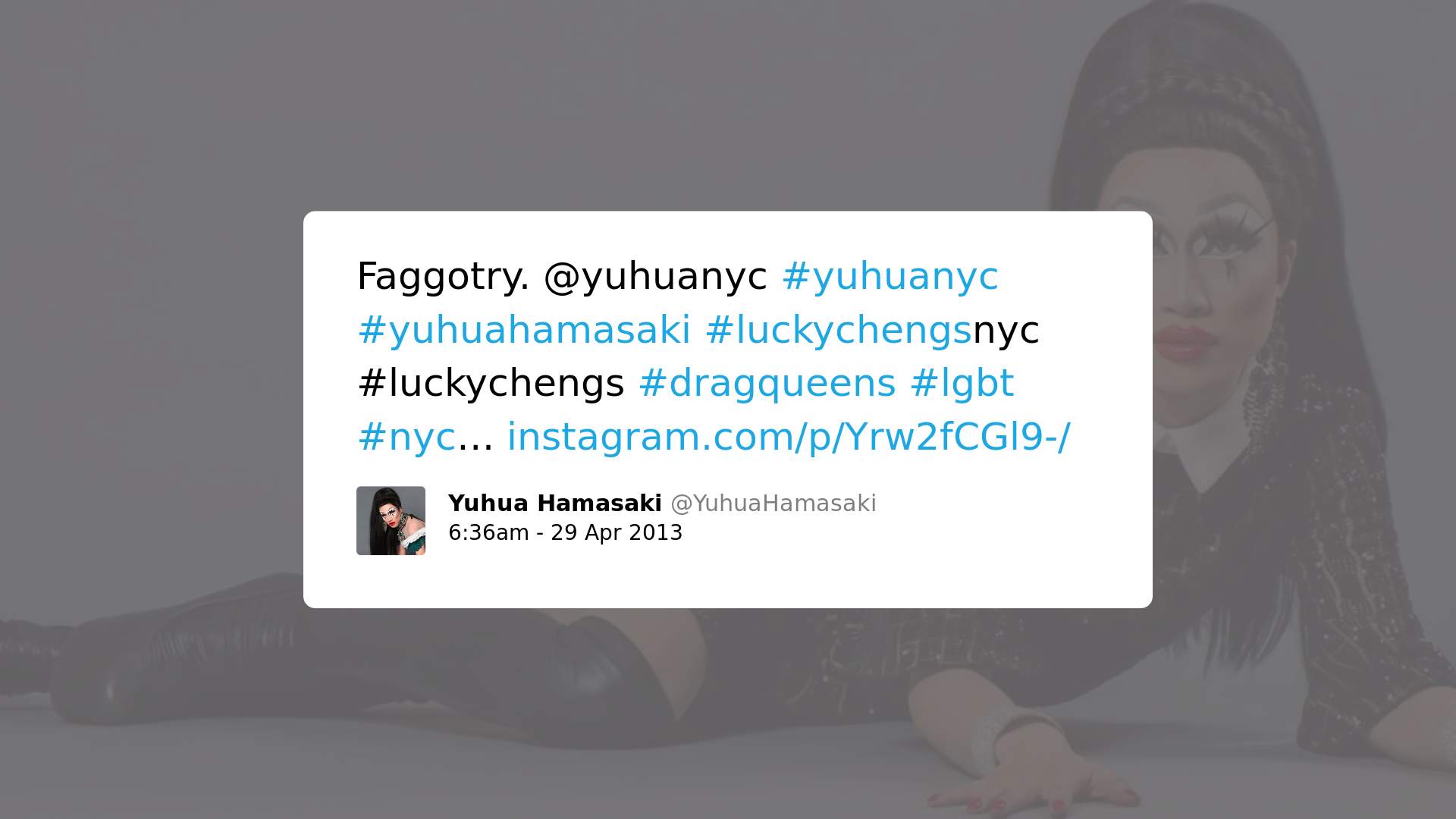
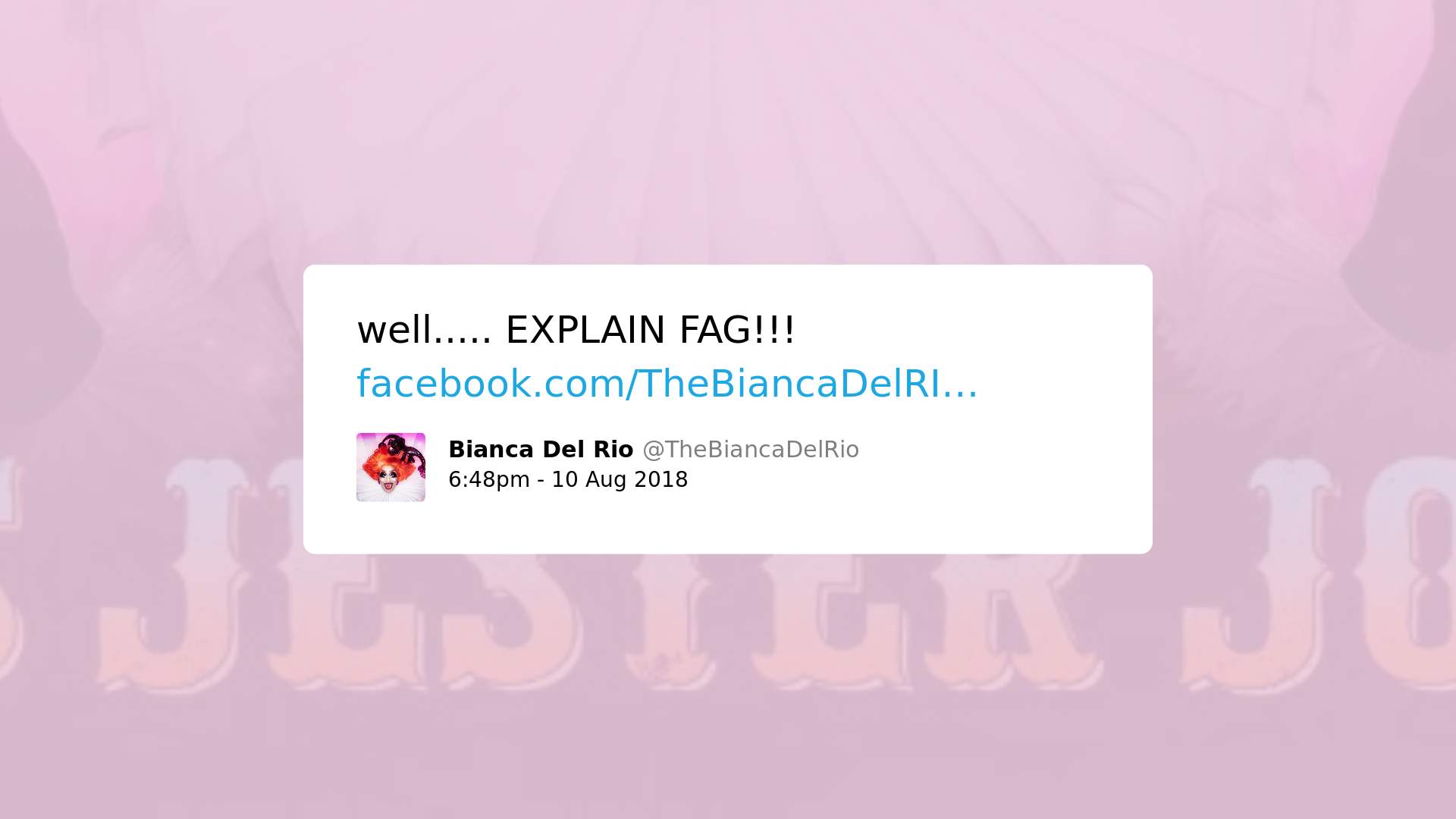
4. Podem até empregar linguagem tóxica, mas têm valor social ou político, denunciando discurso discriminatório de caráter homofóbico, misógino e/ou racista:



Aqui estão alguns exemplos de tweets de supremacistas brancos promovendo ideias que poderiam ser consideradas ‘discurso de ódio’, mas que foram considerados com baixo nível de toxicidade pelo Perspective:


Futuro do discurso e da expressão de grupos subalternizados
Considerando os códigos de comunicação da comunidade LGBTQ, particularmente das drag queens, o uso do Perspective – bem como de outras tecnologias similares – para moderação de conteúdo nas plataformas de internet poderia prejudicar o exercício da liberdade de expressão de membros da comunidade. Isso porque a inteligência artificial ainda não consegue analisar o contexto social do discurso, muitas vezes falhando em reconhecer o seu valor – como na prática da comunidade LGBTQ de reapropriação de palavras consideradas tóxicas e de seu uso para desenvolver uma “casca grossa” nos membros da comunidade com o objetivo de protegê-los contra quem deseja atacá-los. Nesse caso, é provável que decisões automatizadas usando IA venham a suprimir conteúdo legítimo de membros da comunidade LGBTQ – o que é particularmente interessante considerando que essas ferramentas foram desenvolvidas justamente para lidar com discurso de ódio direcionado a grupos marginalizados, tais como a comunidade LGBTQ. Se essas ferramentas podem acabar prejudicando a expressão de membros da comunidade e a denúncia do que consideram conteúdo tóxicos, danoso ou odioso, provavelmente não são uma boa solução.
No longo prazo, deve também haver discussão mais profunda sobre como essas ferramentas podem impactar, modificar e modelar a forma por meio da qual nós todos nos comunicamos: se uma IA considera a palavra bitch como “inapropriada” ou “tóxica”, isso significa que nós devemos parar de utilizá-la? Se computadores decidirem o que é “tóxico” na internet, o que isso significaria para o futuro da comunicação e para a forma como decidimos nos expressar, dentro e fora da internet?