
InternetLab Reporta – Consultas Públicas nº 04
As consultas públicas sobre a regulamentação do Marco Civil e sobre o anteprojeto de lei de Proteção de Dados Pessoais continuam. Confira abaixo como foi a terceira semana em números e polêmicas.
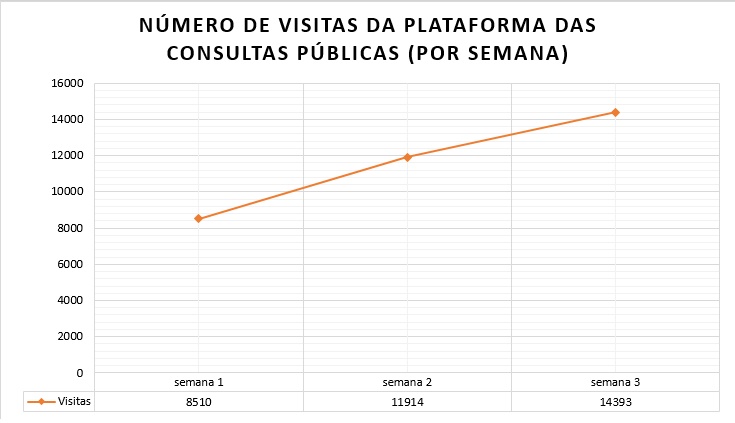
Números e estatísticas

Regulamentação do Marco Civil: acesso a dados por “autoridades administrativas”
Um ponto discutido na regulamentação do Marco Civil é o de como deverá ser feita a guarda e disponibilização de “registros de acesso” e “dados cadastrais” dos usuários de Internet. Com o objetivo de preservar provas que permitam identificar usuários, a lei obriga que os provedores de aplicações (buscadores, redes sociais e todos os serviços a que temos acesso pela rede) e as operadoras de telecomunicações guardem registros das atividades e da conexão dos usuários, os preservando em sigilo. No caso destes registros, apenas um juiz pode requerer a sua disponibilização a terceiros, uma garantia da privacidade do usuário.
Preocupações sobre a regulamentação neste ponto apareceram em tópico criado pelo diretor do InternetLab, Francisco Brito Cruz. O comentário foi endossado por Rafael Zanatta, líder de projeto e pesquisador do Lab, e pelo participante Mário Augusto. Vale lembrar que o InternetLab, além de fomentar e informar sobre o debate público como instituição, também adotou uma postura de inventivo a contribuições individuais de seus membros (diretores, pesquisadores e estagiários). A ideia é prezar pela valorização da plataforma de discussão e pelo pluralismo acadêmico dentro da própria equipe de pesquisa.
Brito Cruz coloca em debate a regulamentação do parágrafo 3º do artigo 10 do Marco Civil. Este parágrafo trata do acesso a dados cadastrais de usuários por “autoridades administrativas”. Tais dados não gozam do mesmo sigilo dado aos registros de atividades e de conexão.
Art. 10. A guarda e a disponibilização dos registros de conexão e de acesso a aplicações de internet de que trata esta Lei, bem como de dados pessoais e do conteúdo de comunicações privadas, devem atender à preservação da intimidade, da vida privada, da honra e da imagem das partes direta ou indiretamente envolvidas. (…)
3o O disposto no caput não impede o acesso aos dados cadastrais que informem qualificação pessoal, filiação e endereço, na forma da lei, pelas autoridades administrativas que detenham competência legal para a sua requisição.
A preocupação é expressa em três pontos. Em primeiro lugar, explica que a regulamentação precisa fazer a diferenciação entre os dados protegidos por sigilo (e só passíveis de acesso por ordem judicial) e os demais dados cadastrais, de forma que não seja possível obter acesso a dados protegidos sem o crivo do Judiciário: “[p]ara atingir as garantias previstas no caput (…) deve estar claro na regulamentação que estes dados cadastrais só podem ser acessados com a indicação de um nome de usuário ou outra informação pertencente à conta de serviço do usuário de Internet em questão”. O receio é de transformar duas proteções em uma: de posse de um “registro de acesso a aplicação” (que consiste em um IP e um horário de alguma atividade na Internet) a autoridade poderia pedir dados cadastrais ligados a esta conexão sem pedir o “registro de conexão” (que são dados sobre como a conexão foi utilizada a partir do IP) a um juiz.
Em segundo lugar, a contribuição pede uma definição no decreto sobre quais são as “autoridades administrativas” que poderão requerer dados cadastrais. Segundo Brito Cruz, a escolha das autoridades, a ser feita no decreto, deve seguir o princípio da finalidade. Deve haver uma uma conexão entre a função da autoridade administrativa e seu pedido por dados cadastrais. Além disso, o próprio pedido deveria ser acompanhado de uma justificativa. A ideia seria realizar formalizar o controle e evitar pedidos sem fundamento.
Por fim, Brito Cruz ressalta que é direito do usuário de Internet o acesso a todas as informações que dizem respeito à coleta, uso, armazenamento, tratamento e proteção de seus dados pessoais, inclusive os fornecidos em um cadastro (garantido pelo Marco Civil em seu art. 7º, inciso VIII). Toda vez que uma autoridade administrativa requerer dados cadastrais, o cidadão deve ser informado, mesmo que essa finalidade seja investigativa. Obviamente, haverá exceções em que o sigilo é necessário, mas estes casos devem ser explicitados no decreto.
Dados pessoais: o que são dados anônimos? Eles devem ser protegidos?

O participante Bruno Bioni (Mestrando em Direito na USP e Pesquisador Visitante no Centro de Tecnologia, Sociedade e Direito da Universidade de Ottawa) lançou na plataforma uma série de observações e sugestões que buscam problematizar a diferença entre dados pessoais e dados anônimos (incisos I e IV do artigo 5º do anteprojeto).
O que Bioni indica estar em jogo é o equilíbrio entre privacidade dos dados pessoais dos usuários e todas as possibilidades de inovação e aprimoramento de serviços através do tratamento de dados anônimos a partir do cruzamento de grandes bases de dados.
Segundo ele, o anteprojeto abre um porta para abusos ao definir dados anônimos como dados não passíveis de reidentificação “tendo em conta o conjunto de meios suscetíveis de serem razoavelmente utilizados para identificar o referido titular”.
O problema seria que alguns dados seriam considerados anônimos (e, portanto, não protegidos como dados pessoais) mesmo quando reidentificáveis, desde que a forma de reidentificação não fosse considerada um “meio razoavelmente utilizado”. O participante, portanto, sugere uma melhor definição do que seriam “meios razoáveis”.
Bioni ainda sugere que os dados anônimos sejam incluídos no escopo da lei. Sua ideia é que as proteções dadas aos dados pessoais também sejam extendidas aos anônimos. A diferença é que, para os anônimos, não seria necessário o consentimento do usuário para o processamento e tratamento. O participante defendeu que isso garante a privacidade do usuário e a capacidade de inovação do mercado, já que dados devidamente anonimizados não deverão lidar com o “obstáculo” do consentimento.
O usuário afirma que esta última sugestão está alinhada com a percepção de especialistas de que, na verdade, não existem dados 100% anônimos (não reidentificáveis) que são ao mesmo tempo úteis para fins de tratamento e inovação. Por esse motivo, não se deve retirar toda a proteção aos dados anônimos, já que sempre haverá o “perigo” de reidentificação.
Para aprofundar a questão e comentar este tema levantado por Bruno Bioni, o InternetLab convidou o Centro de Tecnologia e Sociedade da FGV DIREITO RIO, representado pela pesquisadora Jamila Venturini e pelo seu gestor Luiz Fernando Moncau. O convite segue a linha do InternetLab Reporta de contar com comentários sobre os temas polêmicos das consultas públicas.
Afinal, dados anônimos estão mesmo fora da área de aplicação do anteprojeto de lei?
Comentário: Jamila Venturini e Luiz Fernando Moncau (pesquisadora e gestor do Centro de Tecnologia e Sociedade da FGV DIREITO RIO, respectivamente)
Se por um lado a redação atual do anteprojeto adota no artigo 5º inciso I uma definição abrangente de dados pessoais – que inclui dados relacionados à pessoa identificada ou identificável -, por outro, no inciso IV do mesmo artigo, dados anônimos são definidos de forma separada como aqueles em que não é possível se identificar o titular utilizando-se de meios razoáveis. Uma vez que no artigo 1º afirma-se que a lei dispõe sobre o tratamento de dados pessoais, parece haver uma exceção geral quanto aos dados anonimizados. Ainda que possam haver diversas interpretações sobre esse ponto, o aparente conflito pode gerar insegurança jurídica no que diz respeito ao escopo de uma futura Lei de Proteção de Dados Pessoais, principalmente se consideramos que a prática de anonimização de dados após certo período é corrente no mercado.
Além disso, esse tipo de exceção pode dar margem a uma relativização da proteção conferida à privacidade, especialmente nos casos em que práticas de desanonimizição são utilizadas para se identificar o titular. É importante destacar que especialistas têm apontado para a fragilidade do conceito de anonimização de dados. Para Cory Doctorow, “Quando uma regulamentação afirma que algum dado é “anônimo”, ela está desconectada das melhores teorias da ciência computacional” (para mais informações, veja).
Uma boa prática seria estabelecer critérios claros para determinar o quê seriam dados realmente anônimos e garantir que uma autoridade responsável pela implementação da lei – um órgão competente, como previso no texto atual do anteprojeto – possa revisar esses critérios com base nos desenvolvimentos tecnológicos futuros. Outra alternativa seria a de tornar efetivamente responsável aquele que adotar práticas falhas de anonimização pelos danos causados a um indivíduo que venha a ter seus dados pessoais eventualmente expostos. Se por um lado, isso traria um incentivo a que certas informações sejam efetivamente deletadas ou desassociadas de um banco de dados anonimizado, por outro poderia desestimular práticas de big data. Com a evolução da tecnologia, existirá realmente banco de dados que não seja desanonimizável? E se não existir, faz realmente sentido excluir esses dados da proteção da lei?
Dentro do que diz o anteprojeto, a diferença entre dados anônimos e dados pessoais está realmente apenas na possibilidade ou não de reidentificação?
Comentário: Jamila Venturini e Luiz Fernando Moncau (pesquisadora e gestor do Centro de Tecnologia e Sociedade da FGV DIREITO RIO, respectivamente)
Uma primeira interpretação sugere que um dado pessoal seria aquele capaz de levar diretamente a uma pessoa identificável (como um CEP, um endereço de IP, um identificador único de celular, etc.), enquanto o dado anônimo não poderia ser identificável nem com uso de “meios suscetíveis de serem razoavelmente utilizados para identificar o referido titular”. No entanto, nota-se que a definição atual de dados anônimos parece sugerir que sempre poderão haver meios – não razoáveis – para a reidentificação. Se é esse o caso, a diferença entre dados pessoais e anônimos residiria finalmente na conceituação de quais seriam meios razoáveis: se a reidentificação pode ser feita utilizando-se um meio razoável, estaríamos falando de um dado pessoal, caso contrário, o dado seria anônimo.
Nesse caso, parece adequado que o legislador forneça mais critérios para que se possa interpretar o que são meios razoáveis pra identificar o titular de um dado. O problema dessa alternativa é a de iniciar uma disputa interminável no campo legislativo, com barganhas acentuadas sobre os critérios de interpretação. Tal como na Europa, o lobby pelos interesses privados já avança no sentido de afirmar os benefícios do Big Data e a necessidade de excluir os dados anônimos de qualquer proteção. Os benefícios de qualquer atividade são inquestionáveis, mas a proteção dos direitos em um contexto de crescente potencial da tecnologia para invasão da privacidade merece especial atenção. E esse é o objetivo da lei. Tal como na Europa, este deve ser um ponto a levantar muita polêmica no decorrer do processo legislativo. Mais informações sobre técnicas de anonimização e seu debate na Europa podem ser encontradas aqui.
Por Dennys Antonialli, Jonas Coelho Marchezan, Francisco Brito Cruz e Mariana Giorgetti Valente